Guest blog post by Ethan Clark, IDEA_Lab@EH Intern (Summer 2025)
While I had an understanding of IDEA’s general mission before getting involved this summer, I knew next to nothing about the project’s methodology. What exactly was ‘Linked Open Data’ (LOD), and what could it offer that other means of information management for cultural heritage might not? At first, it sounded to me like abstract technical jargon, but Linked Open Data is nothing more than what it sounds like: a means of cataloguing data, which in our case are the tens of thousands of artifacts, buildings, and information garnered from past excavations of Dura-Europos. LOD is then distinguished by being universally accessible (open), and having metadata interconnected with all entries (linked). IDEA works entirely within a LOD framework known as Wikidata, which structures an item’s data in statements with a ‘subject (item) — predicate (property) — object (value/item) — qualifier’ information flow. For example, the Wikidata item for Dura-Europos includes a statement using the property ‘inception’, value ‘300 BCE’ and property-item qualifier ‘sourcing circumstances- circa.’
My workflow for the first few weeks centered around getting acquainted through hands-on experience. This initially consisted of filling gaps in existing entries, eventually creating new items using the project’s established data models (i.e, information mapping blueprints for general categories of items), and then zeroing in on inscriptions as my area of focus. Inscriptions turned out to be a great case study of LOD’s ability to democratize information, given how rife epigraphy can be with field-specific notations and terminology—let alone the near-century old Dura scholarship. Wikidata was the perfect tool for streamlining this material into a faithful yet far more comprehensible form, and it was incredibly rewarding to adopt a fascinating but antiquated discipline in a modern digital context.
In the latter half of the summer, I shifted to a different project: researching and populating an entry for a triumphal arch and its accompanying inscription located just outside the city. This introduced me to architecture as a discipline, which I discovered had quite a bit of overlap with epigraphy. Their similarity somewhat makes sense, especially in situations like this one, where an inscription is itself an architectural element. But to my surprise, the architectural sources I worked with were often just as filled with jargon and conjecture as the epigraphical material I’d worked with previously. Although I did successfully create a thorough entry after lots of trial, error, and consultation, a confluence of exceptions conspired to make modeling this arch uniquely thorny. For starters, even after sifting through every single triumphal arch listed in Wikidata, I was unable to find a single existing instance of the types of information I wished to reflect. Whereas I had previously had the luxury of referring to data models, I was now in far more uncertain territory. Several issues would arise throughout this process—ambiguous location, outdated information, and a fragmented double-sided inscription, to name a few—but the most exceptionally difficult to deal with was its myriad of individual components and each’s uncertain present condition and whereabouts. How could we clearly reflect that the attic was never found but had to have existed, the molding was found in 1931 but is since unattested, and one of its pillars remains in situ as of 2010? I eventually settled on making use of the ‘state of conservation’ property like so:
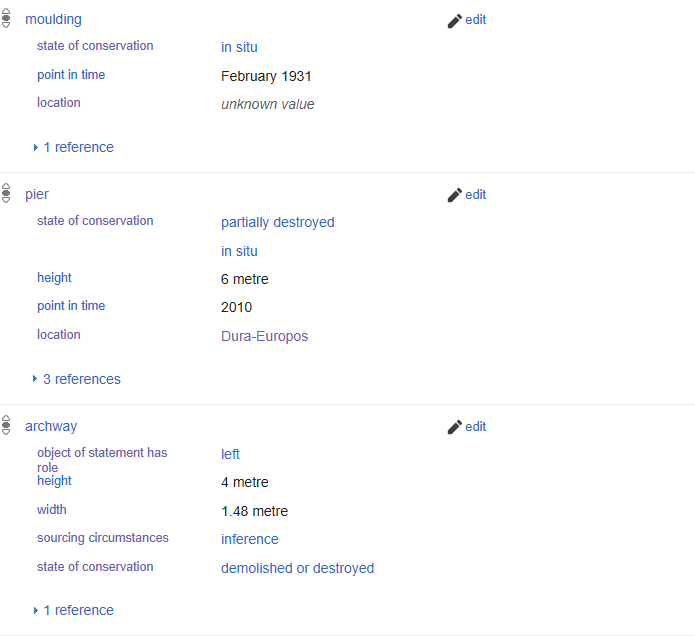
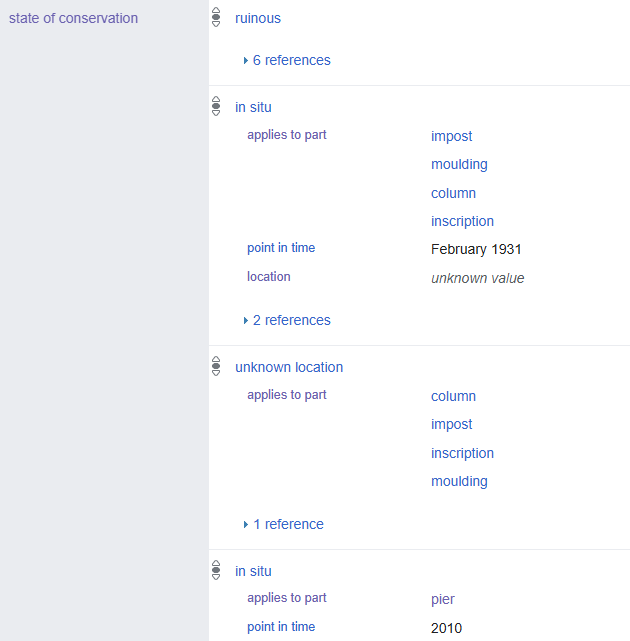
My first foray into Linked Open Data this summer allowed me to see for myself how useful it could be as an archiving methodology. First and foremost, I now appreciate how crucial comprehensive data models are for projects of this magnitude. Not only do they standardize and streamline the creation of more basic entries, but lessons learned from trickier arch-style cases can then be integrated to improve the model going forward. The arch project also forced me to recognize the importance of clarity and concision when attempting to reflect complex information. At some points, I realized that my efforts to diligently reflect the detail of my source material had resulted in me replicating their inaccessibility—one of the very issues that the project seeks to address. While it’s important to try and incorporate as much info from our primary sources as possible, it’s equally vital that this be done in a thoughtful and broadly understandable manner. Last but not least, this arch project enabled me to explore Wikidata’s amazing data visualization and mass upload tools. During my aforementioned search for analogs to the arch, I noticed that most other Roman triumphal arch entries lacked metadata explicitly marking them as ‘Roman’. After manually identifying which of the arches were built in the Roman era, I added the appropriate ‘culture- Ancient Rome’ statement en masse using the software OpenRefine. With this statement in place, Wikidata’s query service allowed me to map the location of every Roman triumphal arch item.
On a bigger-picture level, working with Wikidata has shown me the extent to which any process of collecting and categorizing data is inherently subjective—informed by individual biases and blind spots. Even when striving for complete objectivity, the power to decide how information should be labeled, if it should be included at all, and which other parties merit a voice in this decision-making remains in human hands. But this isn’t to say that it’s impossible to critically engage with source material and information systems as a whole, with close attention paid to author, audience, and intent. Having to draw from the field reports of Dura’s initial excavation, my main source on the arch, was really illuminating with this in mind. Though technically in the public domain, so many prerequisites are required to truly access these reports: prior knowledge of the site and its relevant ancient cultures, academic convention and jargon, and English (if not Greek, Latin, French, etc.), at bare minimum. There’s also the matter of what the reports may omit: perhaps a small artifact deemed not worth including, or the valuable and uncredited contributions of local community members. How do we then acknowledge and address the limitations of our sources when transferring their data into a digital database? There’s no simple answer, but it’s essential for projects like ours to promote a diversity of input and remain aware of possible limitations in decision-making.
In my time with IDEA thus far, I’ve been introduced to an entirely novel system of organizing information, and had the chance to delve into ancient architecture and epigraphy. I dealt with the difficulties of reconciling the often obscure conventions of these fields, and learned through experience how to reflect important data from dated sources without replicating their more antiquated and problematic aspects. But my exploration of traditional disciplines in such an innovative context did more than show me the ins and outs of Linked Open Data; it also challenged my preconceptions around the objectivity of hard data, and shed light on the direct and indirect ways in which information is shaped and siloed by those who classify and control it. Thanks to my experience this summer, I feel much more equipped to critically approach sources and systems of information—even beyond the scope of this project.


2. Reconstruction of arch with remaining elements superimposed, by Yale archaeologist A.H Detweiler, 1937.
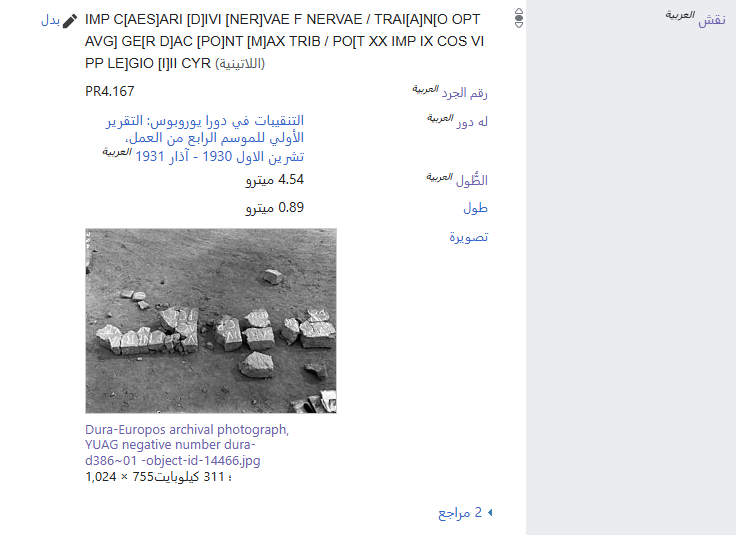
3. ‘Inscription’ statement from triumphal arch entry, shown here in Arabic.
Funding for student research via the IDEA_Lab@EH is generously provided by the Bard College BOLD fund for Undergraduate Research.