Guest blog post by Charlotte Behrens, IDEA_Lab@EH Intern (summer 2025)
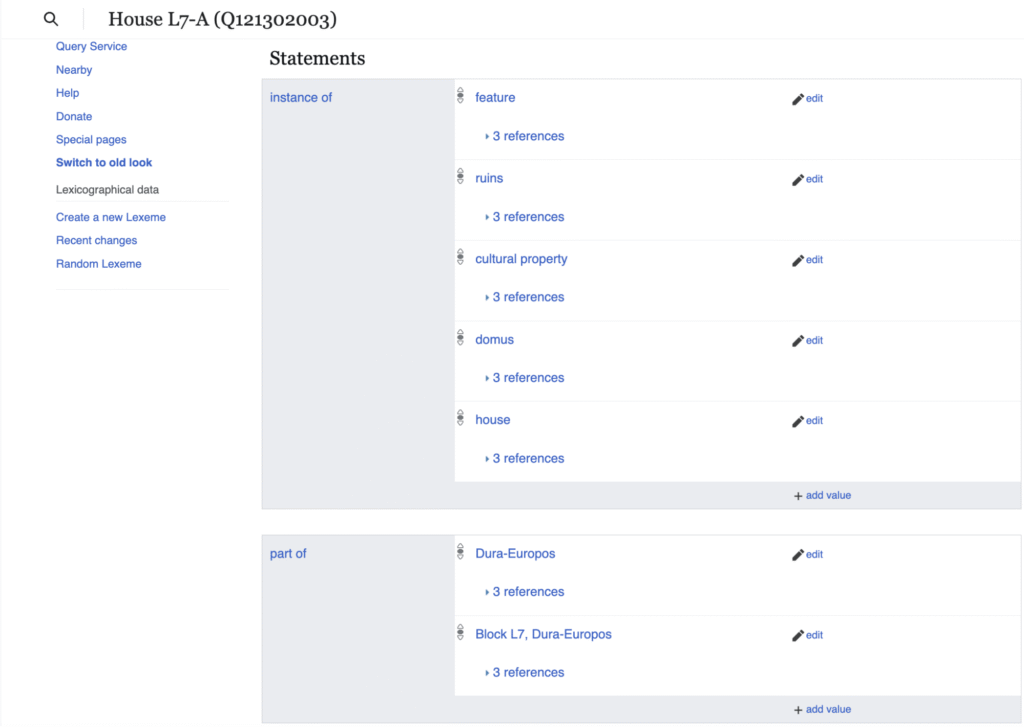
My work within the IDEA_Lab@EH in summer 2025 was dedicated to creating and enhancing metadata relating to House L7-A from the archeological site of Dura-Europos, Syria. House L7-A, also referred to as the House of the Roman Scribes, was a private residential and military-occupied home within the city. Substantially preserved in the aftermath of the siege of Dura, it yielded a significant number of archaeological artifacts during the Yale-French excavation campaign of 1932–1933. Evidence of paintings, inscriptions, and fallen ceiling tiles dedicated to deities, members of the Roman military, and residents of the home can all be found throughout various rooms of the house, establishing L7-A as an assemblage of material from which it is possible to recover clues for understanding ancient life at Dura (Baird 2014, p. 138-142).
Over the course of the summer, I worked with published excavation reports and other secondary literature, archival photographs, and documents related to House L7-A to compile a record of its construction, history, imagery, and excavated materials. This research has deepened my ability to analyze primary sources such as field registers and photographs, while also becoming adept at using research tools like unique identifiers (accession numbers, negative numbers, etc.) to locate archival material in databases such as the Yale University Art Gallery and JSTOR—an essential skill not only for research on Dura-Europos but for any work within archives or collections. Beginning my work with IDEA with little-to-no experience with Linked Open Data (LOD) or archival research methods, I’ve found that familiarizing myself with accession numbers, footnotes, plate numbers, and other forms of identification has improved my productivity in all contexts of academic research.Creating and enriching LOD through the platforms Wikidata and Wikimedia Commons, I have created hundreds of human- and computer-legible statements that express relationships among records for architectural remains, artifacts, and archival materials related to House L7-A. First, creating a Wikidata item/page for House L7-A and inputting information such as significant dates, people, events, sources, and locations, I was able to structure a public-facing assemblage of key data related to the context. Hierarchically nested with respect to the parent concept of House L7-A item, I created linkable pages for each room within the house, allowing me to connect archival images, artifacts, inscriptions, and residents to the corresponding Wikidata items for specific rooms, creating an interconnected, multilingual record of the house and its contents. When I express referenced facts and interpretations in English, thanks to the efforts of a global community of editors, users elsewhere can read those statements in their native language. In this way, LOD can transform static, standalone archival records into a cohesive, globally accessible network of knowledge that preserves the complexity of House L7-A while making it legible across languages and audiences.
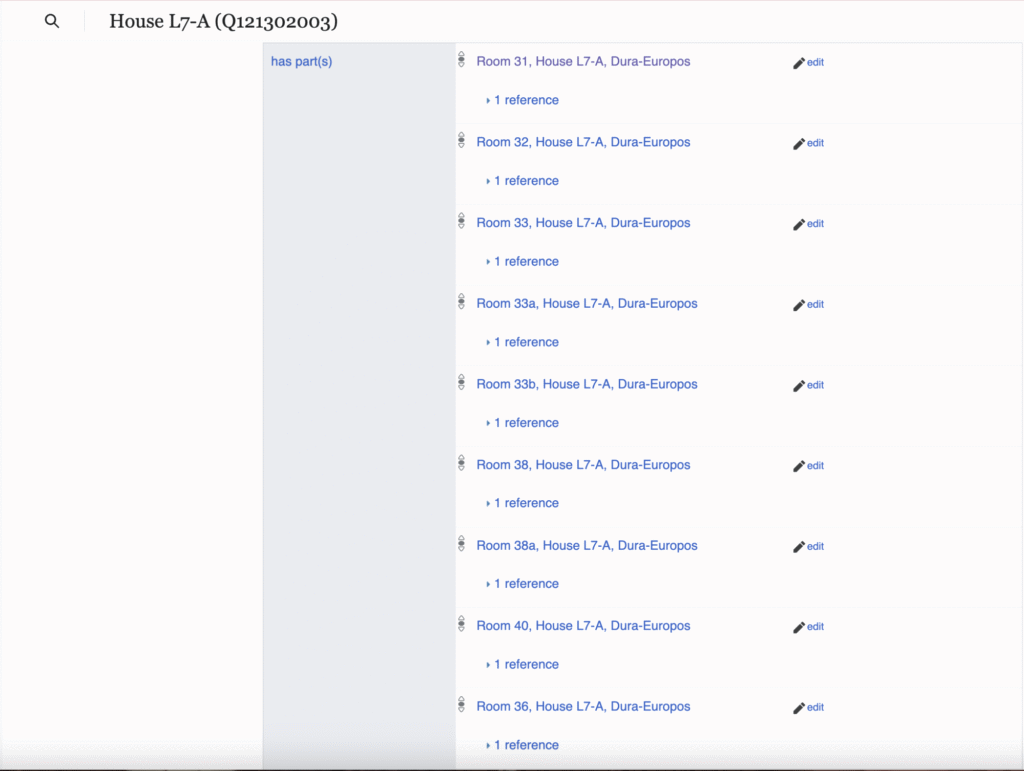
The item created for a wall painting of Aphrodite and Eros, found in room 38 of House L7-A, can serve as an example of how Wikidata functions through using LOD. Despite the fact that published academic research on the wall painting can be found in The Excavations at Dura-Europos: Preliminary Report of the Sixth Season of Work, October 1932 – March 1933 and other secondary sources related to the house, the painting’s online presence was quite limited, making it difficult for users to be able to trace this artifact back to its original location and context within the site. With the fragment of the wall painting presumably residing in the National Museum of Damascus, the only evidence of this object outside of the preliminary report and field register is found through the Yale University Art Gallery’s excavation photos via JSTOR. Because the object itself is not located within Yale’s collection, no unique identifier was assigned to it; instead, negative numbers exist as references for archival field photographs of the painting, rather than for the physical object. Prior to my work this summer, no online database record existed for the wall painting, but through Wikidata and Wikimedia Commons I established a Commons category to group relevant field documentation and linked it to both a newly created record for the artifact and an existing record for House L7-A.

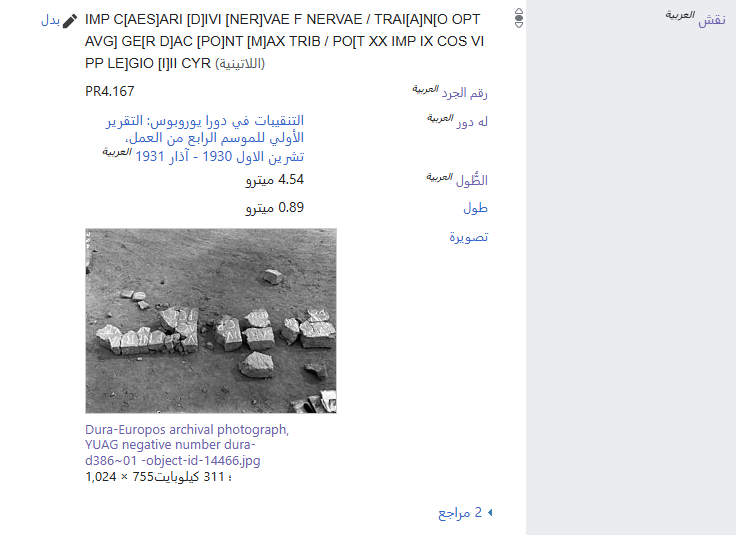
Once a Commons category was created for the object, a Wikidata item could be made to structure and consolidate dispersed information related to the painting. Below, we can see the multilingual functionality of Wikidata in action. In the example showcased here, information that I input in English as individual metadata statements each referenced back to the source of the datapoint, is immediately legible in other languages.
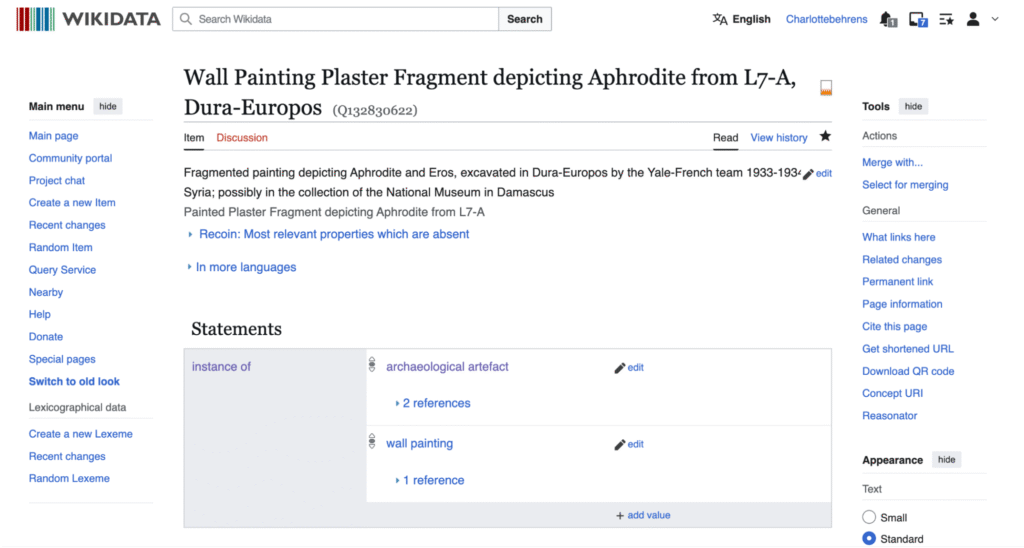
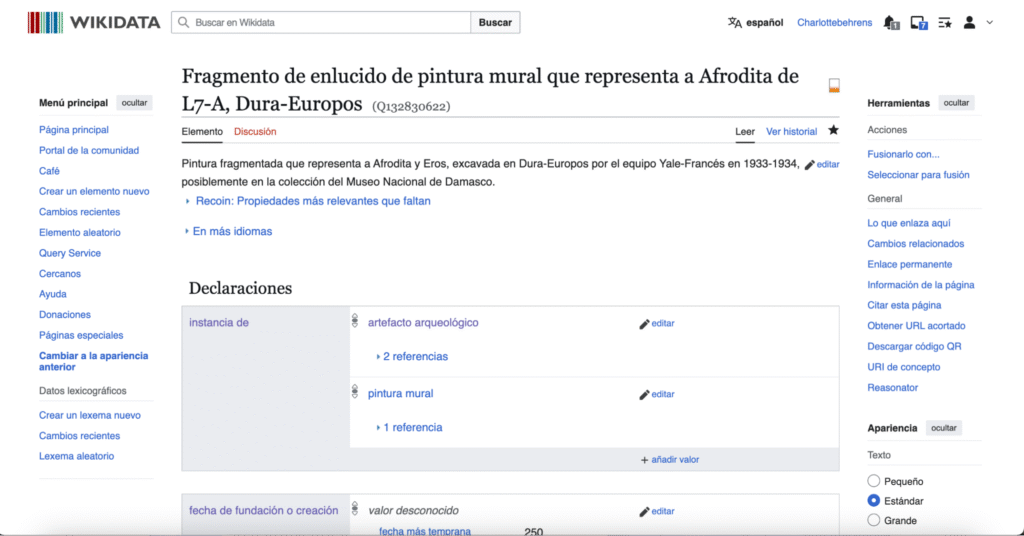
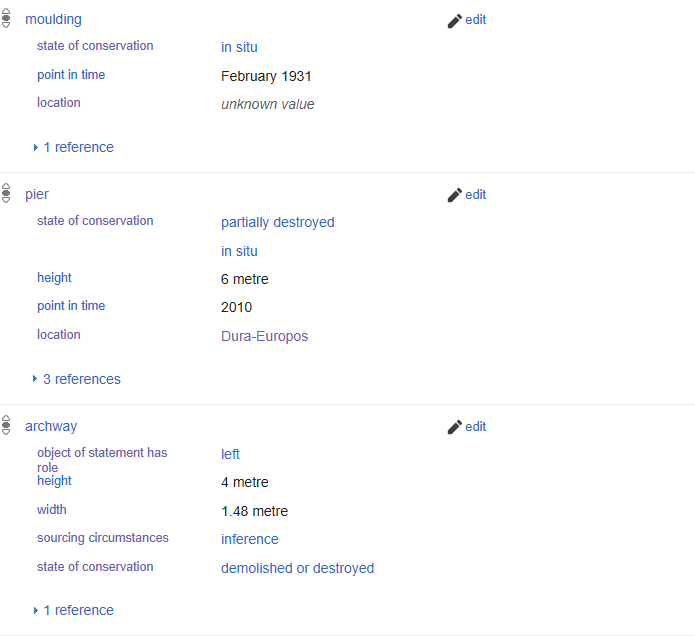
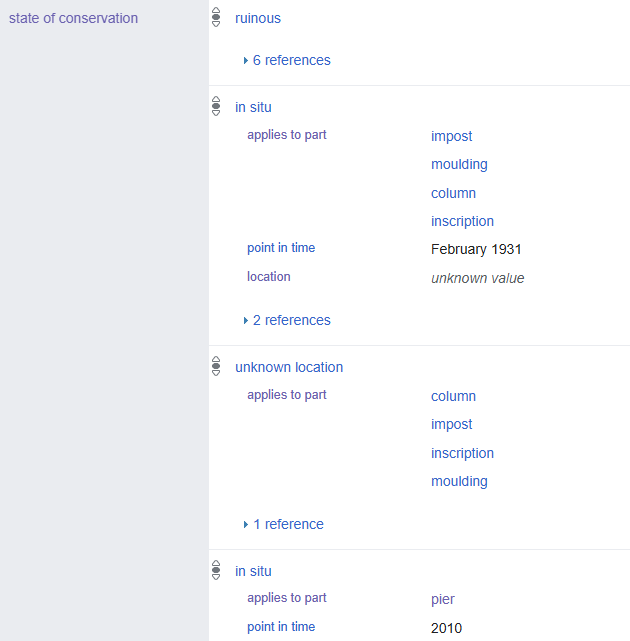
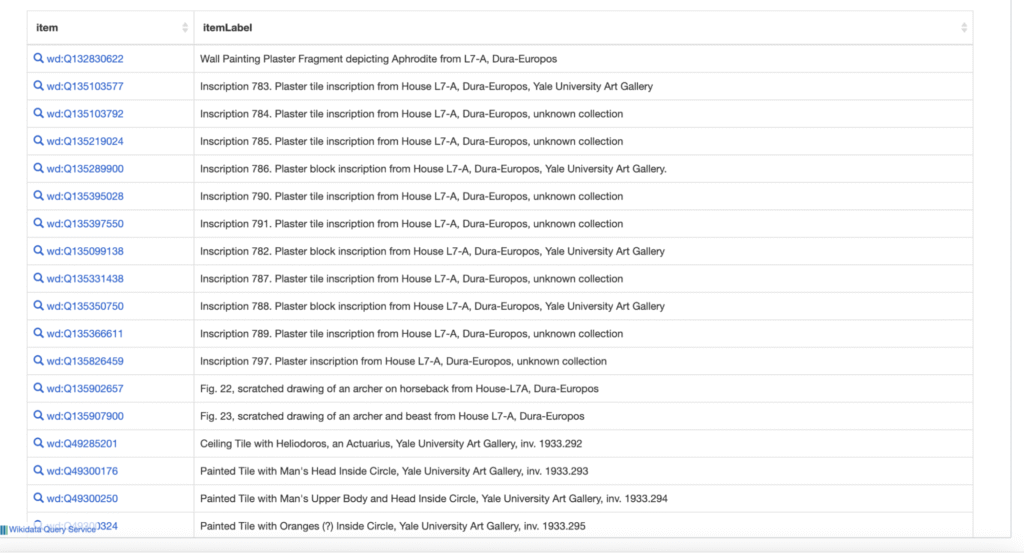
All Wikidata items and the properties used to connect them are automatically assigned a language-agnostic code that stands in for the entity represented by the record, and users all over are working to map corresponding human-readable labels to the unique codes for shared concepts (ex: location of discovery; bronze) in hundreds of world languages. Wikidata users can set their interface to display in their preferred language, and the system automatically draws from the pool of user-contributed multilingual labels mapped to unique codes representing things and ideas to display a record’s complete metadata in the selected language. Individual statements on the record for the wall painting serve as the building blocks that connect the object to related people, places, and concepts. Adding a ‘location of discovery’ statement not only shows a user the exact room number this object originated from, but also connects the wall painting to the broader categories of House L7-A and Dura-Europos. In providing the ‘House L7-A’ value to this statement, the wall painting of Aphrodite and Eros is now searchable amongst all other archaeological artifacts found within the house, effectively digitally recreating the assemblage dispersed by excavators when they removed and divided up finds a hundred years ago. Using Wikidata’s query service and the ‘location of discovery’ property, architectural remains, paintings, and inscriptions from L7-A’s various rooms are visualizable to users despite residing in different collections or being left in situ at Dura.
References are another essential facet of Wikidata’s use as a research tool. For every assertion made about the wall painting of Aphrodite, at least one scholarly source is provided to substantiate the claim. I relied on both primary and secondary sources to create the statements for this item, with each value verified through reference URLs, page numbers, and plates, so that users can easily locate relevant information. Beyond these references, Wikidata also allows the wall painting—as an artifact and primary source for the ancient past—to be directly linked to archival documentation of its discovery. The ‘described by source’ property lists the references that inform the item, while the ‘depicted by’ statement connects the painting to excavation photographs and related archival materials, which are themselves primary records of the inherently destructive excavation process that occurred.

For example, Dura-Europos archival photograph YUAG negative number dura-g66b~01 serves as a field photograph of the painting’s discovery, linking the artifact itself to its excavation record and thereby situating it within both its ancient and modern contexts.
What Wikidata provides to its users is an interconnected understanding of the spaces, finds, and people tied to Dura-Europos. Rather than isolating the wall painting of Aphrodite and Eros as a standalone object, its record links the artifact to the broader history of the site. Establishing a virtual, multilingual, searchable, and well-referenced digital record for this item positions the painting within the context of House L7-A as a whole through records of discovery, inception, location, materials, and references. Seeing the painting in relation to its architectural setting and associated finds allows for a fuller understanding of its cultural significance — something that would likely be missing from a traditional museum display where the object is removed from its findspot. Through this compilation of resources and virtual publications, the Wikidata item reconstructs the wall painting’s context as closely as possible, highlighting both the artifact itself and the environment of its recovery.
Furthermore, establishing records for non-accessioned objects, those missing from catalogs or archival databases, was an important aspect of enriching the metadata of L7-A. Although there is significant information on Dura-Europos available online, the existing digital landscape offers only a partial picture of what was actually excavated. Excavation reports reveal inconsistencies in what was recorded or preserved at the time, and the archival record is fragmented across institutions: some material is held by Yale, some by the National Museum of Damascus, and some remains untraceable outside of the preliminary field record. Many artifacts, such as painted ceiling tiles, inscriptions, and graffiti drawings that tell us about the occupants of the house, the presence of soldiers, or traditional hunting scenes, are especially difficult to locate digitally—even if they are discussed in print. A significant part of my work involved creating the first-ever records for digitally-invisible items that reports and other archival materials list as left on site or else ceded to the National Museum in Damascus. By bringing these into Wikidata and Wikimedia Commons, I was able not only to make these finds visible online, but also to link them back to the rooms, sources, and individuals that give them meaning within the broader context of the site.
Overall, my work with the IDEA_Lab@EH and in digital archiving has focused on learning how to research rigorously, extract information from and reference available sources, and express the outcomes of my research using LOD methods. I have learned to pay close attention to footnotes, plate numbers, indexes, and other research elements that are highly relevant to my work—not only as an Art History student, but also as someone interested in pursuing a career in archives/collection management. I am currently working at Bard’s Montgomery Place campus as an assistant digital archivist, collaborating with collections specialists to revise and digitize both existing and new archives into online databases such as JSTOR Forum. I have found that the process of accessioning these objects is quite similar to working in Wikidata, with the primary differences being the proximity to the materials being worked with and digital accessibility, whether that be through multilinguality or open-access platforms. While the practice of digitization within these two archives is similar, the work with the IDEA lab differs in regards to its international accessibility. Working through the multilingual site of Wikidata, the information I am asserting publicly in English and anchoring with references to strong sources passes previously inaccessible information into Arabic. In providing a translatable account of field records, excavation reports, and academic research on Dura-Europos, this opens up the possibility for new perspectives and connections to emerge, drawing out people, objects, and ideas that might otherwise remain invisible in English-only or institutionally bound archives. Linked Open Data in the context of the IDEA lab allows a conversation between English and Arabic-speaking users, expanding access to archaeological records and inviting interpretations that reflect a wider range of cultural and scholarly perspectives on the site.
Funding for student research via the IDEA_Lab@EH is generously provided by the Bard College BOLD fund for Undergraduate Research.